查看系统负载情况
1 | top -c |
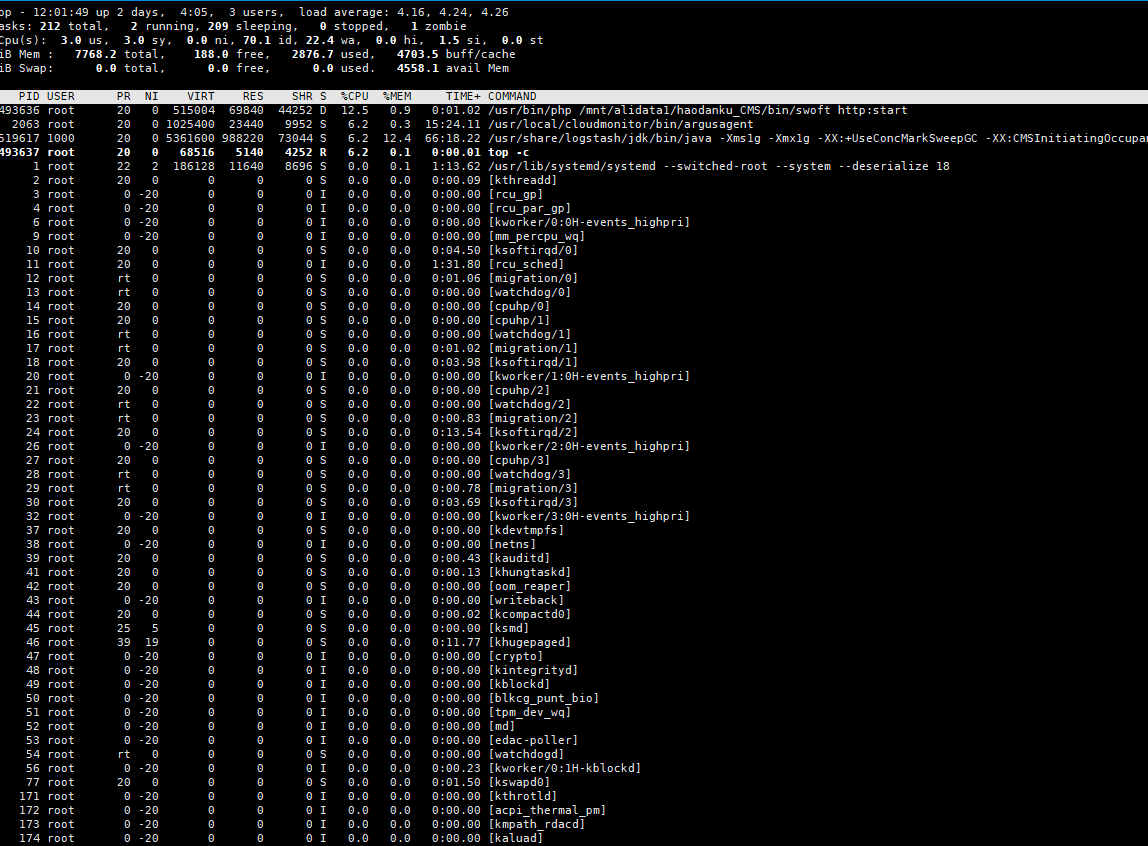
/usr/bin/php /mnt/alidata1/haodanku_CMS/bin/swoft http:start 进程为 D 状态(不间断睡眠状态)
持续观察发现该进程 PID 存在变化,猜测可能存在进程守护在维护此命令进程。
tips:Linux 进程状态
1 | supervisorctl status |

发现存在两项服务,且 prod_cms 在 6 秒前触发运行过。
1 | # 通过locate命令,查看supervisord运行相关文件夹 |
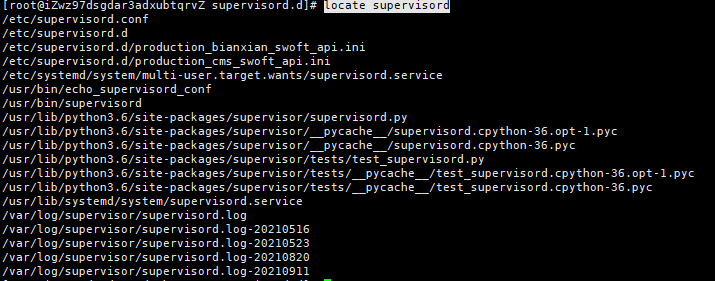
配置目录为 /etc/supervisord.d/
1 | # 进入配置目录 |
查看 prod_cms 对应 配置文件 production_cms_swoft_api.ini
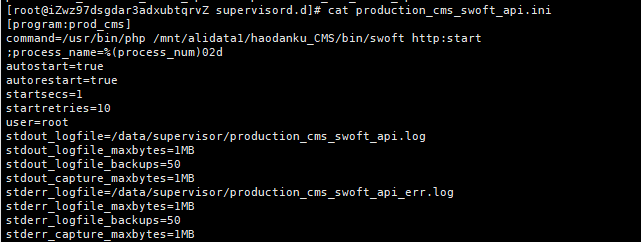
发现配置有输出运行错误日志,查看错误日志
1 | # 通过tail命令查看最后50行信息 |
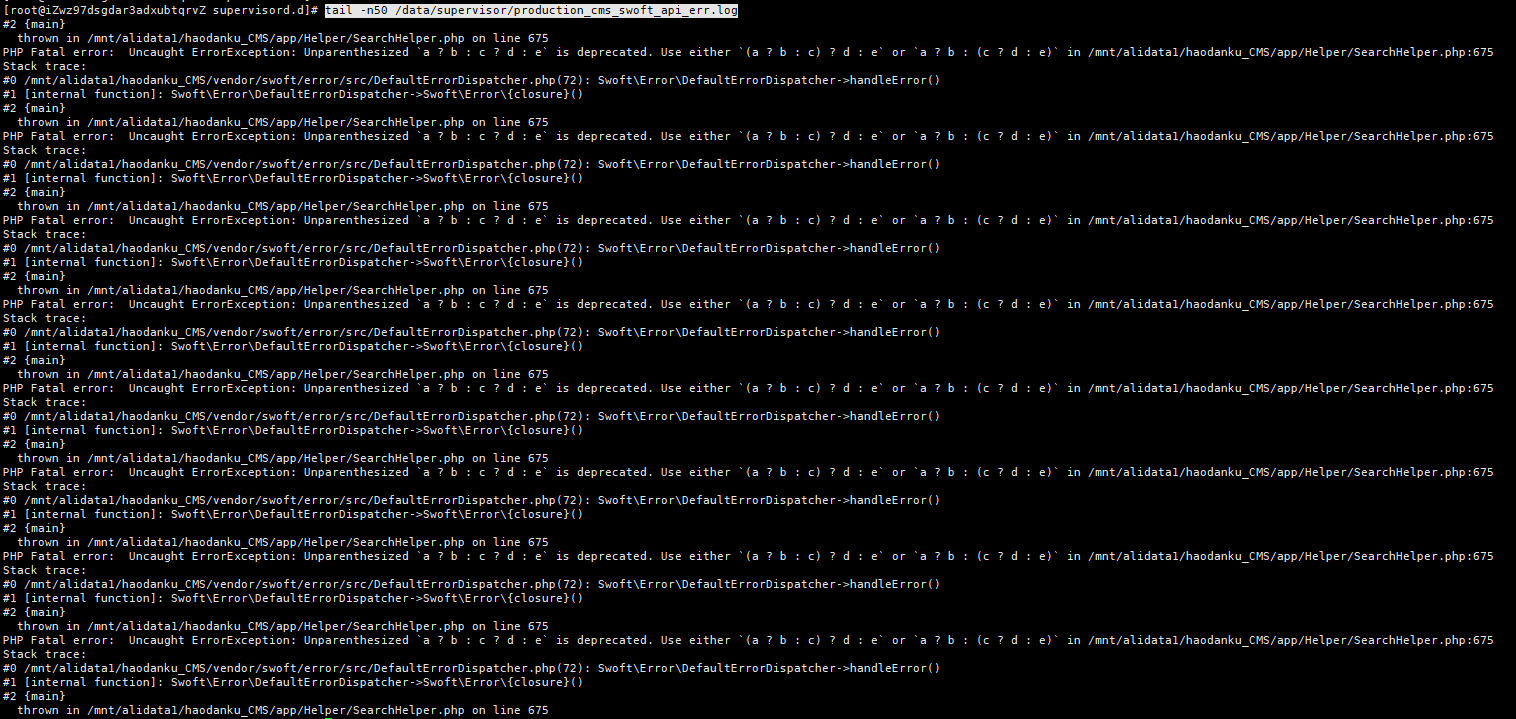
发现运行命令时,代码抛出异常信息。查看报错信息,发现代码当中存在三元运算符错误。
解决
问题解决
定位到问题代码
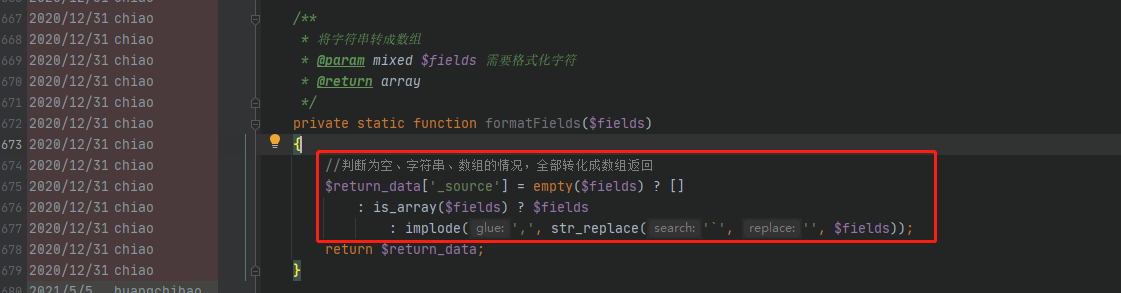
修复代码问题

停止守护进程服务
1 | supervisorctl stop prod_cms |
运行服务,查看是否存在问题
1 | php /mnt/alidata1/haodanku_CMS/bin/swoft http:start |
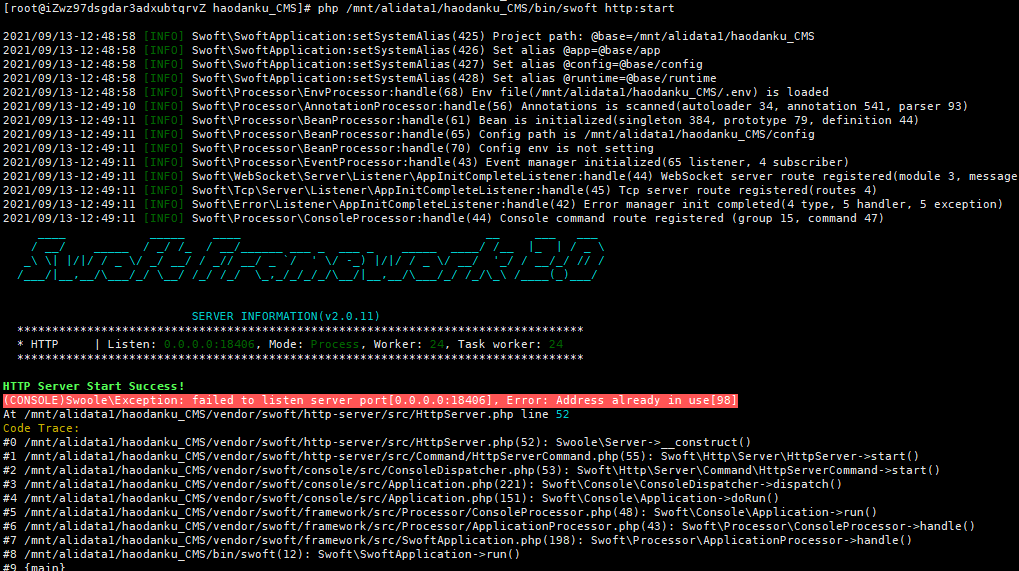
环境异常
运行服务,发现端口 18406 存在占用
1 | # 查看 18406端口 |
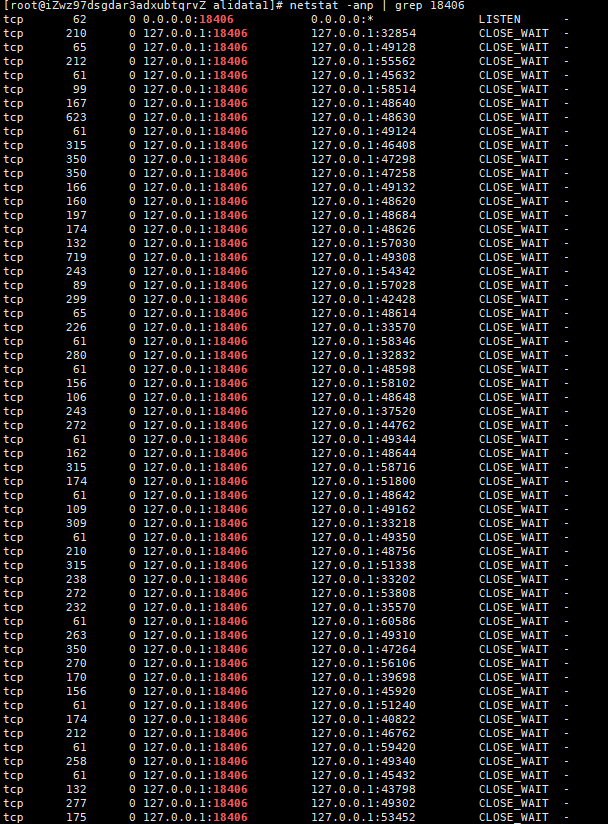
发现大量处于 CLOSE_WAIT 状态的 TCP 连接
1 | # 查看18406端口的tcp连接情况 |

存在 63 个 CLOSE_WAIT 状态的连接
tips:netstat 命令使用
解决 CLOSE_WAIT 问题
为什么会出现 CLOSE_WAIT
当客户端因为某种原因先于服务端发出了 FIN 信号,就会导致服务端被动关闭,若服务端不主动关闭 socket 发 FIN 给 Client,此时服务端 Socket 会处于 CLOSE_WAIT 状态(而不是 LAST_ACK 状态)。通常来说,一个 CLOSE_WAIT 会维持至少 2 个小时的时间(系统默认超时时间的是 7200 秒,也就是 2 小时)。如果服务端程序因某个原因导致系统造成一堆 CLOSE_WAIT 消耗资源,那么通常是等不到释放那一刻,系统就已崩溃。
方法一:通过修改 TCP/IP 的参数
1 | vi /etc/sysctl.conf |
net.ipv4.tcp_keepalive_time = 1800
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_keepalive_intvl = 15
1 | # sysctl.conf - end |

