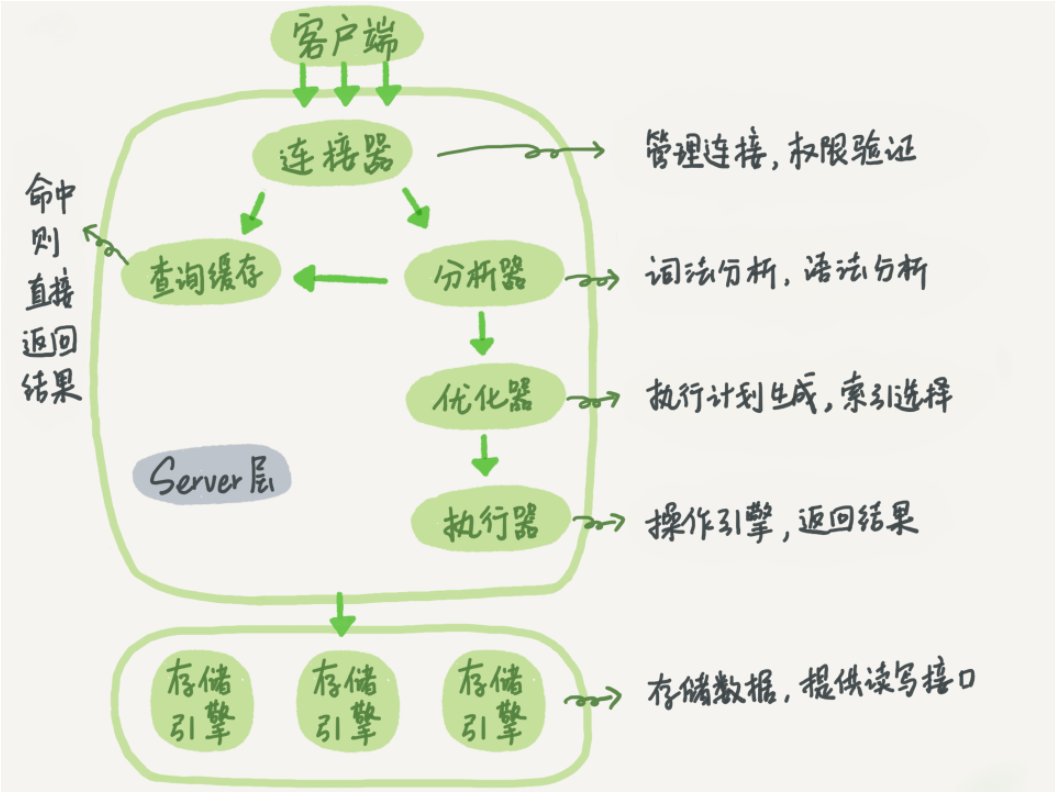
Select 语句的执行流程
第一步:连接器
连接器负责跟客户端建立连接、获取权限、维持和管理连接。如果用户名密码验证通过后,连接器会到权限表里面查出你拥有的权限。之后该连接的权限验证都依赖于刚查出来的权限。
第二步:查询缓存
当获取连接后,一条 SELECT 语句会先去查询缓存,看之前是否执行过。如果获取到缓存后就执行返回,不然继续后面的步骤。
大多数时候不建议使用缓存,因为只要一个表更新,这个表上的所有缓存数据就会被清空了。对于那些经常更新的表来说,缓存命中率很低。MYSQL8 版本直接将查询缓存的整块功能删掉了。
第三步:分析器
分析器首先会做“词法分析”,MYSQL 会识别出 SQL 语句里面的字符串是什么以及代表什么。接下来就是“语法分析器”,分析 SQL 的语法问题。
第四步:优化器
优化器会对 SQL 的执行顺序,使用哪个索引进行优化。确定 SQL 的执行方案。
第五步:执行器
执行器执行 SQL 语句会对权限进行校验,如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。
Update 语句的执行流程
update 语句除了会执行上面的五步,还会涉及两个重要的日志模块。
两个重要的日志模块
redo log (重做日志)
redo log 是 innodb 所特有的,当有一条更新语句时,innoDB 引擎会先把记录写到 redo log 中,然后更新内存,这时候更新就算完成了。innoDB 会在合适的时候将这个记录更新到磁盘中去。
特点:redo log 是固定大小的,属于循环写。redo log 是物理日志,记录的是“在某个数据页上做了什么修改”。有了 redo log ,InnoDB 可以保证数据库发生异常重启的时候,之前提交的记录不会丢失,这个能力为 crash-safe。
binlog(归档日志)
binlog 属于 server 层的日志,是逻辑日志,记录的是这个语句的原始逻辑,比如给“id =1 的一行的某个字段+2”。binlog 是追加写入的,binlog 写到一定的大小后切换到下一个,不会覆盖之前的。
更新语句的内部流程
update t set n = n+2 where id =1
- 执行器先找引擎找到 id=1 的那一行,如果这一行的数据页已经在内存中则直接返回给执行器。否则先从磁盘读入内存中,然后在返回。
- 执行器拿到了引擎返回的数据行,把这个 n 值+1,得到新的行数据,然后调引擎的接口写入这行新数据。
- 引擎将这行数据更新到内存中,同时将这个更新操作记录到 redo log 里,此时 rodo log 属于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务了。
- 执行器生成这个操作的 binlog,并把 binlog 写入磁盘。
- 执行器调引擎的提交事务接口,引擎把刚刚写入的 redo log 的状态改为 commit 状态,更新完成。
两段式提交
redo log 的写入分为两部分,是为了保证这两份日志的逻辑一致。
相关配置
redo log 用于保证 crash-safe 能力。
innodb_flush_log_at_trx_commit 这个参数设置成 1,表示每次事务的 redo log 都直接持久化到磁盘。
sync_binlog 这个参数设置成 1 的时候,表示每次事务的 binlog 都持久化到磁盘。

